《人工智能:计算Agent基础》——3.5 无信息搜索策略
本文共 5788 字,大约阅读时间需要 19 分钟。
本节书摘来自华章计算机《人工智能:计算Agent基础》一书中的第3章,第3.5节,作者:(加)David L.Poole,Alan K.Mackworth 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.5 无信息搜索策略
一个问题给定了图和目标,但并没有给出从边界中选择哪条路径。这是搜索策略的任务,一个搜索策略指定如何从边界中选择路径。通过改变在边界中选择路径的实现方法从而可以得出不同的搜索策略。79
这部分介绍了三种不考虑目标节点位置的所谓无信息搜索策略(uninformed search strategy)。直觉上,这些算法不关心它们要到哪里去,直到找到目标节点并报告成功。3.5.1 深度优先搜索第一个策略是深度优先搜索(depth-first search)策略。在深度优先搜索中,边界的动作像一个先进后出的堆栈(stack)。这些元素被逐次地压入栈中。在边界中被选择并撤销的节点肯定是最后一个入栈的元素。【例3-6】 考虑图3-5中的树形图,假设初始节点是树的根(在顶部的节点),节点从左到右排序,所以最左边的邻居最后被压入栈 在深度优先搜索中,节点扩展的方向并不依赖于目标节点的位置。图3-5中,我们将首批扩展的16个节点用数字标记出来了。阴影节点表示这16步检索完成后,边界路径上的最终节点。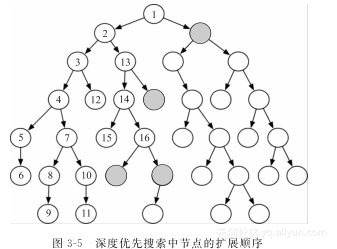
- 时间开销
- 空间开销
- 结果的质量以及准确性
时间开销、空间开销以及结果的准确性都是算法输入的函数。计算机科学家们所探讨的渐进复杂度(asymptotic complexity),规定了时空开销是如何随着算法的输入量的增加而增长的。算法对于输入大小n有时间(或空间)的复杂度函数O(f(n)),读作“大Of(n)”,这里f(n)是关于n的函数,如果存在常数n0和k,对于所有的n>n0, 都有算法的时间或空间开销少于k×f(n)。这个函数的最常见形式是指数函数,如2n、3n、1.015n;多项式函数,如n5、n2、n、n1/2;或对数函数,如logn。一般来说,指数函数算法比多项式函数算法复杂度增长更快,相应的,多项式函数算法比对数函数增长的快。
当输入大小为n时,如果存在常数n0和k,对于所有的n>n0,都有算法的时间或空间开销大于k×f(n),就称算法有时间或空间复杂度Ω(f(n))。一个算法如果有复杂度O(n)和Ω(n),那么它就有时间或空间的复杂度Θ(f(n))。通常情况下,不能说一个算法的复杂度是Θ(f(n)),因为大多数算法输入不同,时间开销也不同。因此,当比较算法时,必须确定问题分类。当通过时间、空间或准确性某个方面衡量出算法A比算法B更优,则意味着:- A最坏的情况比B的最坏的情况好;
- 在实践中,A能更好运行。或者在考虑典型性问题的平均情况时,A运行的平均情况比B好;
- 由你描述哪类问题使用算法A比B好,所以算法的优劣取决于要解决的问题;
- 对于任何的问题,A都比B好。
最坏情况的渐进式复杂度往往最容易显现,但它通常是最没用的。如果很容易确定所给定问题是哪一类,通过对问题的特征分类来决定哪种算法更优是最有用的方法。不幸的是,这种特征分类很难。
通过对问题的特征分类来确定哪种算法更优,可以在理论上通过数学方法或在经验上通过建立程序来实现。这些数学定理的有效性只能依赖于作为基础的假设。相似地,基于经验的程序验证只能在测试用例和算法实际的实现方法中有效。我们很容易通过举个反例来反驳一种算法对某类问题更优的猜想,但却很难证明这种猜想。如果第一个分支搜索就得到一个解,那么时间复杂度就与路径的深度呈线性关系,它只考虑这条路径上的元素,以及它的兄弟姐妹。最坏情况的时间复杂度是无限大。即使存在一个解,如果这个图是无限的或者循环的,深度优先搜索会陷入无限的分支然后永远找不到解。如果图是有限的树,前向分支系数最大是b,深度为n,那么最坏情况的时间复杂度是O(bn)。【例3-8】 考虑修改前面的图,让Agent在位置之间移动更自由,得出图3-6,一条无限的路径从ts指向mail,然后回到ts,再返回mail,如此循环往复。显然,深度优先搜索将沿着这条路径永远搜索下去,而不会考虑到b3或者o109等可选择路径。前5次反复使用深度优先路径搜索算法得到的边界如下:[〈o103〉][〈o103,ts〉,〈o103,b3〉,〈o103,o109〉][〈o103,ts,mail〉,〈o103,ts,o103〉,〈o103,b3〉,〈o103,o109〉][〈o103,ts,mail,ts〉,〈o103,ts,o103〉,〈o103,b3〉,〈o103,o109〉][〈o103,ts,mail,ts,mail〉,〈o103,ts,mail,ts,o103〉,〈o103,ts,o103〉,〈o103,b3〉,o103,o109〉]
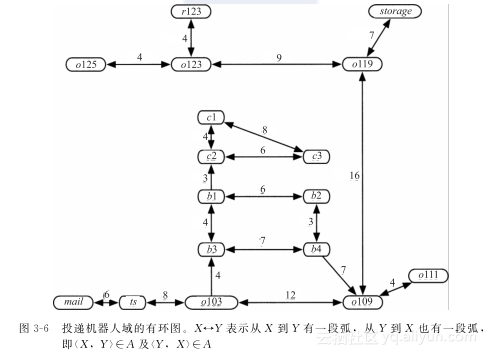
可以通过不考虑有环路径来优化深度优先搜索。
因为深度优先搜索对邻居加入边界的顺序敏感,这一点必须仔细对待。这个顺序可以是静态的(这样邻居的顺序固定)或者是动态的(邻居的顺序由目标节点决定)。深度优先搜索适用的条件:- 空间是被限定的;
- 存在许多解,可能路径很长,尤其当几乎所有路径都导致一个解时;
- 节点邻居的压栈的顺序可以调整,以便在第一次尝试中就找到解。深度优先搜索不适用的条件:
- 当图是无限的或者图中有环的时候,有可能陷入无限的路径中;
- 解路径存在于隐蔽的深度,因为在这种情况下可能要搜索很多条长路径才能发现短路径结果。深度优先搜索是许多其他搜索算法的基础,如迭代搜索。
3.5.2 宽度优先搜索
在宽度优先搜索(breadth-first search)中,边界是用一个先进先出(FIFO)队列实现的。因此,最开始从边界中选择的路径是最早进入队列的。这个方法意味着从初始节点出发的路径按照弧数目多少的顺序依次产生。在每一个阶段中,选择弧最少的那条路径。84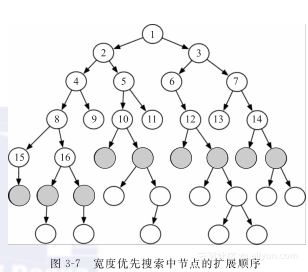
- 不存在空间问题;
- 想找最少弧的路径;
- 可能有很少的解,但是至少有一个短路径解;
- 可能存在无限的路径,因为它会遍历所有的搜索空间,即使是无限的路径。
这个算法并不适用于所有的路径都很长,或者有一些可用的启发知识的情况。因为空间复杂度很大,所以它并不常用。
3.5.3 最低花费优先搜索当路径的花费与弧有关时,我们常常想找到总花费最小的路径。例如,对于一个投递机器人,花费可能是两位置之间的距离,我们需要总距离最短的那条解路径。花费也可能是机器人按照弧实施动作所需要的各种资源。一个指导系统的花费可能是学生所需要的时间和精力。在每一种情况下,搜索者都试图找到最低花费的解路径来达到目标。目前为止考虑的搜索算法不能保证找到最低花费的路径,他们完全没有使用弧花费的任何信息。宽度优先搜索首先找到弧数最少的路径,但这未必是最少花费的路径。最简单的能保证找到最低花费路径的搜索方法与宽度优先搜索算法相似。不同的是,它是寻找最低花费的路径,而不是通过扩展路径找最少弧数的路径。这是通过把边界作为一个由花费函数排序的优先级队列来实现的。【例3-11】 看图3-2,考虑图中从o103开始的最低花费优先搜索。唯一的目标节点是r123。这个例子中,路径由最后的节点表示,下标是路径的花费值。最初,边界是[o1030]。下一阶段是[b34,ts8,o10912]。因为b3的花费最小,所以选择了到b3的路径,结果边界变为:[b18,ts8,b411,o10912]。86因为b1的花费最小,然后选择到b1的路径,结果为:[ts8,c211,b411,o10912,b214]。因为ts的花费最小,然后选择到ts的路径,结果为:[c211,b411,o10912,mail14,b214]。然后选择到c2的路径,如此循环。注意最低花费优先搜索是如何逐渐增长路径的,它总是扩展花费值最低的路径。如果一个问题存在解路径,弧线的花费被界定为低于一个正常数且分支系数也是有限的,那么最低花费优先搜索就能确定找到一个最优解(即有最低花费的路径)。而且,最先找到的路径就是花费最低的路径。因为算法产生的路径从最初就是按照路径花费值排序的,所以这个解是最优的。如果存在一个比第一个被发现的解更优的解,它在边界中会被选择得更早。界定的弧花费是用来保证最低花费搜索能找到最优解。如果没有这样的界定,就会有有限花费的无限路径。例如,对于每一个i>0,节点n0,n1,n2,…对应的弧线〈ni-1,ni〉中每一条弧线的花费都是1/2i,这样的话,存在很多形式为〈n0,n1,n2,…,nk〉的路径,它们的花费都小于1。如果有一条弧从n0到目标节点的花费大于或等于1,它将永远都不会被选中。这个就是早在2300年前亚里士多德写到的“芝诺悖论”的基础。像宽度优先搜索,最低花费优先搜索在时间和空间上都是典型的指数函数。它会产生所有的低于解路径花费的从起始节点开始的路径。转载地址:http://wltkx.baihongyu.com/
你可能感兴趣的文章
Django_4_视图
查看>>
Linux的netstat命令使用
查看>>
IntelliJ IDEA 连接数据库详细过程
查看>>
android学习笔记——onSaveInstanceState的使用
查看>>
工作中如何做好技术积累
查看>>
java.lang.UnsatisfiedLinkError:no dll in java.library.path终极解决之道
查看>>
【跃迁之路】【460天】程序员高效学习方法论探索系列(实验阶段217-2018.05.11)...
查看>>
C++入门读物推荐
查看>>
TiDB 源码阅读系列文章(七)基于规则的优化
查看>>
求职准备 - 收藏集 - 掘金
查看>>
jQuery|元素遍历
查看>>
MFC多线程的创建,包括工作线程和用户界面线程
查看>>
我的友情链接
查看>>
FreeNAS8 ISCSI target & initiator for linux/windows
查看>>
PostgreSQL数据库集群初始化
查看>>
++重载
查看>>
Rainbond 5.0.4版本发布-做最好用的云应用操作系统
查看>>
nodejs 完成mqtt服务端
查看>>
sql server 触发器
查看>>
[工具]前端自动化工具grunt+bower+yoman
查看>>